
실습데이터 파일
필요한 라이브러리 불러오기
from statsmodels.tsa.seasonal import seasonal_decompose
import statsmodels.api as sm
from statsmodels.tsa.stattools import adfuller
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from statsmodels.tsa.arima.model import ARIMA
import pmdarima as pm
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import seaborn as sns
import numpy as np # linear algebra
from prophet import Prophet
from prophet.plot import plot_plotly, plot_components_plotly
from prophet.diagnostics import cross_validation
from prophet.diagnostics import performance_metrics
import warnings
warnings.filterwarnings('ignore') # Hide warnings
warnings.simplefilter(action = "ignore", category = RuntimeWarning)
import datetime as dt
import pandas as pd
pd.core.common.is_list_like = pd.api.types.is_list_like
#import pandas_datareader.data as web
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import matplotlib.dates as mdates
import pandas as pd
#from plotnine import *
import io
# we'll use the statistics package to conduct some predictive analytics
import statistics as st
%matplotlib inline
import matplotlib.dates as mdates
from pandas import DataFrame
from pandas import to_datetime
from statsmodels.tsa.stattools import kpss
from statsmodels.tsa.stattools import adfuller
from sklearn.metrics import mean_absolute_error
Python
복사
데이터 전처리
df = pd.read_csv("walmart_cleaned.csv")
# 주별 집계 데이터 테이블을 만들기!
df['Date2']= pd.to_datetime(df['Date'])
#날짜 정렬하기
df = df.sort_values(by='Date2')
#연도 컬럼 빼기
df['year'] = df['Date2'].dt.year # 시계열 데이터인 경우는 dt.year, month 요일 별 값을 추출 가능하다!
# 집계 컬럼만들기
def func(df):
df_sum={}
df_sum['Weekly_Sales'] = df['Weekly_Sales'].sum()
df_sum['Temperature'] = df['Temperature'].mean()
df_sum['Fuel_Price'] = df['Fuel_Price'].mean()
df_sum['IsHoliday'] = df['IsHoliday'].max()
df_sum['CPI'] = df['CPI'].mean()
df_sum['Unemployment'] = df['Unemployment'].mean()
return pd.Series(df_sum, index=['Weekly_Sales','Temperature','Fuel_Price','IsHoliday','CPI','Unemployment'])
df_agg = df.groupby(['year','Date2']).apply(func).reset_index()
df_agg
Python
복사
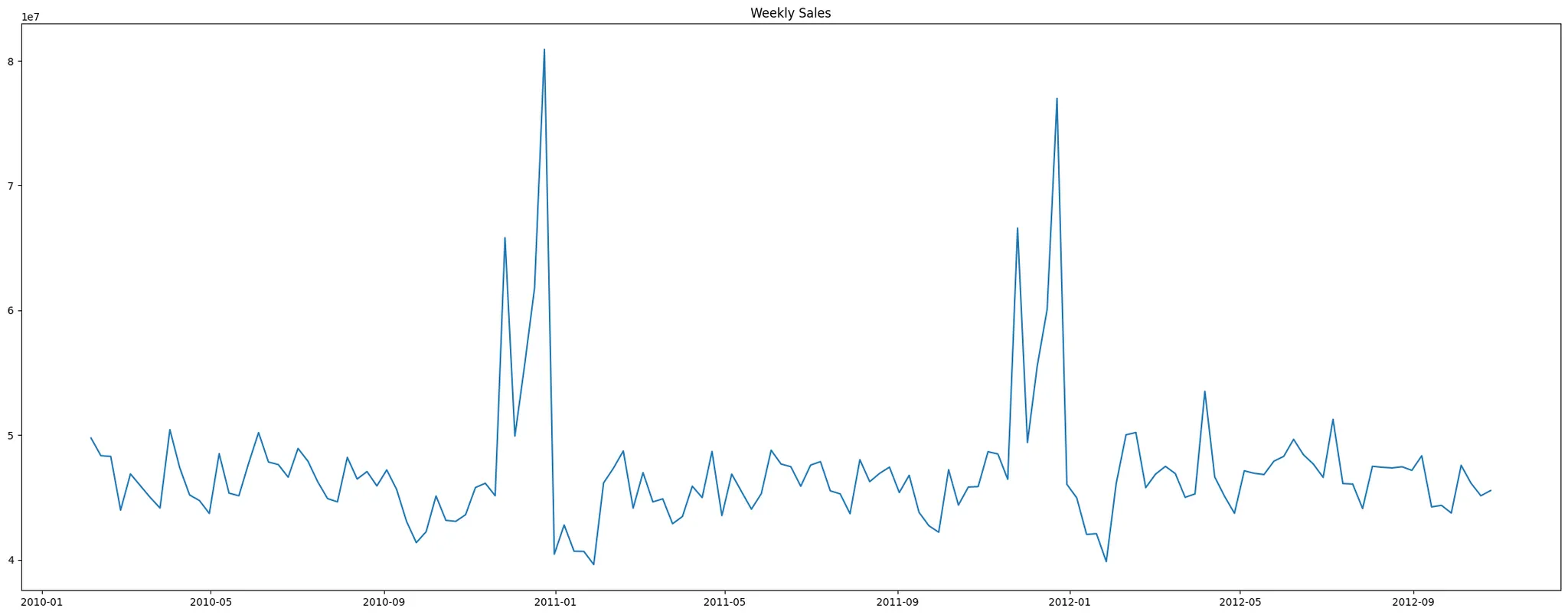
추세와 변동성 시각화
plt.figure(figsize=(27,10))
plt.plot(df_agg.Date2, df_agg.Weekly_Sales)
plt.title('Weekly Sales')
Python
복사
시계열 데이터 분해
#decomp 간단하게 분해하기!
timeseries_decomp = df_agg.loc[:, ['Date2','Weekly_Sales']]
timeseries_decomp.index = timeseries_decomp.Date2
ts_decomp = timeseries_decomp.drop('Date2',axis=1)
decomp = seasonal_decompose(ts_decomp['Weekly_Sales'], model= 'additive', period = 4)
fig = plt.figure()
fig = decomp.plot()
fig.set_size_inches(20,15)
plt.show()
Python
복사
.png&blockId=144b136a-1bb0-8177-9ea3-f58dd71e650f)
ACF, PACF 시각화
fig =plt.figure(figsize=(20,8))
ax1 = fig.add_subplot(212)
fig = sm.graphics.tsa.plot_acf(ts_decomp, lags=60, ax=ax1)
ax2 = fig.add_subplot(211)
fig = sm.graphics.tsa.plot_pacf(ts_decomp, lags=60, ax=ax2)
Python
복사
.png&blockId=144b136a-1bb0-81f2-adc7-c950259eeb40)
ARIMA 모델링 전, 정상성 확인을 위한 ADF 검정
def ADF(ts_decomp):
result = adfuller(ts_decomp.values, autolag='AIC')
print('TEST 진행')
print('ADF Statistics 값 %f' % result[0])
print('p-value 값 %f' %result[1])
print('Lag 값 %f' %result[2])
print('관측 값 %f' %result[3])
print('기각역')
for key, values in result[4].items():
print('t%s: %.3f' % (key,values))
ADF(ts_decomp)
Python
복사
ARIMA
# Arima를 위한 학습셋, 테스트셋 나누기!
train = ts_decomp.loc['2010-02-05':'2012-09-21']
test = ts_decomp.loc['2012-09-28':'2012-10-26']
# ARIMA를 사용하기 위해 p,d,q 값을 파라미터 설정
p,d,q = 2,0,2
model_arima = ARIMA(train['Weekly_Sales'], order=(p,d,q))
model_arima_fit = model_arima.fit()
#결과값 예측하기
pred1 = model_arima_fit.forecast(steps=5)[0]
pred1 = pd.Series(pred1, index= test.index)
#시각
fig, ax = plt.subplots(figsize=(15,5))
graph = sns.lineplot(x ='Date2', y='Weekly_Sales', data= train)
pred1.plot(ax=ax ,color='red', legend=True)
test.plot(ax=ax, color='blue', legend=True)
Python
복사
.png&blockId=144b136a-1bb0-81c2-b125-ed6aea5630e1)