데이터 구간화(Binning)
데이터 구간화(Binning)
연속형 변수를 다룰 때 구간을 나눠서 새로운 변수를 만든다. 이런 과정을 통해서 해당 변수의 스케일이나 분포가 모델에 미치는 영향을 줄일 수 있다.
키라는 변수가 있다고 가정하자
150~159를 150대로, 160~169를 160대로 설정하는 방식을 통해 스케일링이나 분포의 영향을 줄일 수 있다.
1. 변수 구간화의 개념
•
구간 설정 : 연속형 변수를 나눌 구간 설정하여, 미리 개수나 도메인 지식으로 정할 수 있음
•
구간 경계 설정 : 설정한 구간마다 경계 필요
•
이산형 변수로 변환 후 사용할 수 있고, 데이터 마이닝에도 사용할 수 있다.
2. 변수 구간화의 기준
연속형 분수를 여러 구간으로 나눔
•
구간별 평균값으로 평활화할 수 있음
•
중앙값으로 평활화 할 수 있음
•
경계값으로 평활화 할 수 있음
•
도메인 별로 평활화 방법이 달라질 수 있음
Feature_selection 의 영역
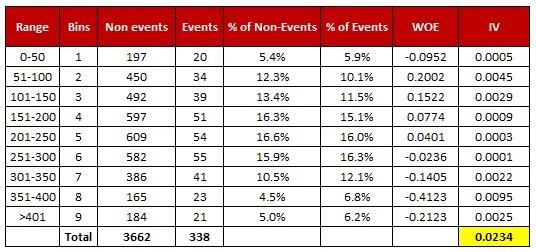
어떤 피쳐를 사용해야할지 모르겠다면, WOE와 IV 방법론을 사용해보자
WOE, IV 변수의 정보량과 예측력을 평가하는데 사용하는 지표이다.
1. WOE
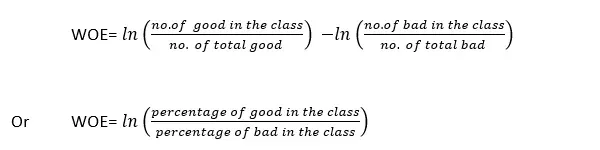
WOE 의 컨셉은 종속변수 대비 독립 변수가 예측력이 얼마나 강한지 설명하는 지표
*상관관계와 비슷한 개념
•
WOE 양수 : 구간 값들이 양성클래스의 발생이 더 관련이 있음
•
WOE 음수 : 구간 값들이 음성 클래스의 발생에 더 관련이 있음
•
WOE 값이 큰 양수 또는 큰 음수 : 해당 구간 값이 예측값과 강한 관계
•
WOE 0인 값: 클래스와 큰 관계가 없다.
2. IV
IV(Information Value)변수의 예측력을 평가하는 데 사용하는 통계적 수치

•
IV <0.02: 유용하지 않은 변수
•
0.02 <=IV <0.1: 약한 예측력
•
0.1 <=IV <0.3: 중간 예측력
•
0.3 <=IV <0.5: 강한 예측력
•
IV >= 0.5, 1.0 이상: 매우 강한 예측력
•
어떤 변수가 타겟과 더 강한 관계를 가지고 있는지 확인하는 것
•
높은 수치라고해서 다 좋은 게 아니라 과적합의 원인이 될 수 있다. 이런 부분은 모델링을 통해서도 같이 크로스 체크 진행해야 한다.