
.png&blockId=144b136a-1bb0-8113-9ce9-e792ad9bd009)

 기하학적으로 OLS 이해하기
기하학적으로 OLS 이해하기
저번 시간에 유도한 OLS estimator를 다른 방법으로 다시 유도해보자. 먼저 우리의 데이터셋이 개의 데이터와 개의 피쳐들로 이뤄졌다고 하자. 이 때 한개의 데이는 개의 피쳐를 갖고 있으므로 벡터로 나타낼 수 있다. 이를 행벡터로 나타내 개의 데이터셋을 행렬로 나타내면 행렬로 나타낼 수 있다. 여기에 절편을 추가하기 위해 원소가 1인 차원 컬럼벡터 를 추가하여 다음과 같이 나타내보자.
구할 회귀계수 도 벡터로 나타내서 와의 선형 방정식을 행렬표현으로 차원 벡터이고 수식으로 나타내면 아래와 같다.
는 오차로 관측되지 않는 확률변수이다. 편의를 위해 기댓값이 0이고 분산이 인 i.i.d 가정을 하겠다.
즉, 예측값은 의 열벡터의 선형결합으로 표현이 가능하고, 따라서 X의 열공간상의 벡터이다. OLS는 실제값과 예측값의 차이인 잔차의 제곱합을 최소화하는 것이 목표이다. 자세한 증명은 생략하겠지만, 직관적으로 이러한 잔차가 의 열공간과 수직을 이룰때에가 잔차가 가장 작음을 알 수 있다. 따라서 를 의 열공간에 정사영시킨 벡터가 OLS의 예측값이다.
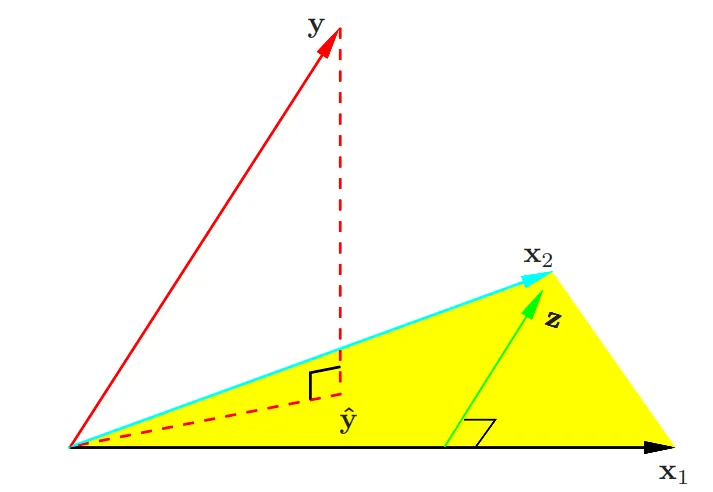
두 벡터가 수직이면 내적값은 0이라는 것을 우리는 알고 있다. 따라서 잔차는 의 열공간의 모든 벡터와 수직이여야 한다. 수식으로 나타내면 다음과 같다.
따라서 최적해는 위 방정식을 풀면 유도된다.
는 hat matrix라고 불리며, 벡터 를 의 열공간에 정사영시키는 행렬이다.
통계적 추론
의 기댓값과 분산을 계산해보자.
보통 오차항의 분산 는 알 수 없으므로, 다음과 같은 추정량을 사용한다.
Note. 를 항등행렬이라 할때, 위 추정량은 불편추정량임을 다음과 같이 보일 수 있다.
추가적으로 오차항이 정규분포를 따른다고 가정하면, 다음이 성립한다.
회귀계수에 대한 가설 검정은 에 대한 귀무가설을 통해 검정하며 아래와 같은 z-점수를 사용한다.
는 의 번째 대각원소이다. 귀무가설 하에서 는 자유도가 인 t-분포를 따른다. 충분히 큰 에 대해서는 정규분포와 큰 차이가 없기에 정규분포를 사용하여도 된다. 즉, 정규분포를 생각해보면 가 큰 값을 가진다는 것은 귀무가설을 기각할 수 있기에 의미 있는 회귀계수라고 볼 수 있다.
또한 신뢰구간은 이다.
만약 의 조합간의 모델 차이를 보고 싶다면 다음과 같은 F-통계량을 사용한다.
은 개의 파라미터를 가진 모델의 잔차제곱합이고, 는 이보다 작은, 첫번째 모델에 포함되는 개의 파라미터를 가진 모델의 잔차제곱합이다. 만약 더 작은 모델이 맞다면, 즉 나머지 개의 회귀계수가 0이었다면 이는 분포를 따른다. 마찬가지로 충분히 큰 에 대해서 을 따른다.