
 EM(Expectation-Maximization) 알고리즘이란?
EM(Expectation-Maximization) 알고리즘이란?
가 주어졌을 때 EM 알고리즘은 다음과 같이 작동한다.
1.
을 초기화한다.
2.
(E-step) 를 계산한다.
3.
(M-step) 를 정의하고 으로 업데이트를 진행한다.
에 대한 임의로 확률분포 를 정의하면 로그가능도 는 다음과 같은 부등식을 따른다.
이는 로그 함수가 단조증가함수라는 사실과 옌센 부등식(Jensen's inequality)을 통해 유도되었다. EM 알고리즘의 목표는 를 통해 로그 가능도의 하한인 를 최대화하는 것이다.
먼저 베이즈 정리에 의해 이다. 이를 이용하여 를 다음과 같이 분해해보자.
위 식의 첫번째 항은 꼴로, 마찬가지로 다음과 같이 옌센 부등식을 이용하여 0보다 작거나 같음을 알 수 있다.
(등식은 일때 성립함을 알 수 있다.)
이를 쿨백-라이블러 발산(Kullback–Leibler divergence)이라고하며, 다음과 같이 표기한다.
Q2. 이는 이전시간에 결정트리에서 배운 엔트로피와 비슷해보인다. 쿨백-라이블러 발산에 대해서 찾아보자.
다시 정리해보자면, 이고, 를 최대화 해야하므로, 이는 가 0이 될 경우이기에 따라서 일 때 최대가 된다.
위의 E-step과 M-step이 어떻게 유도되었는지는 다음과 같다.
정리E-step: 를 고정하여 로그가능도의 하한의 최대를 계산한다. 즉, 매 단계마다 로 둔다.
M-step: 으로 고정하여 최대가 되도록 하는 를 계산하여 를 업데이트한다.
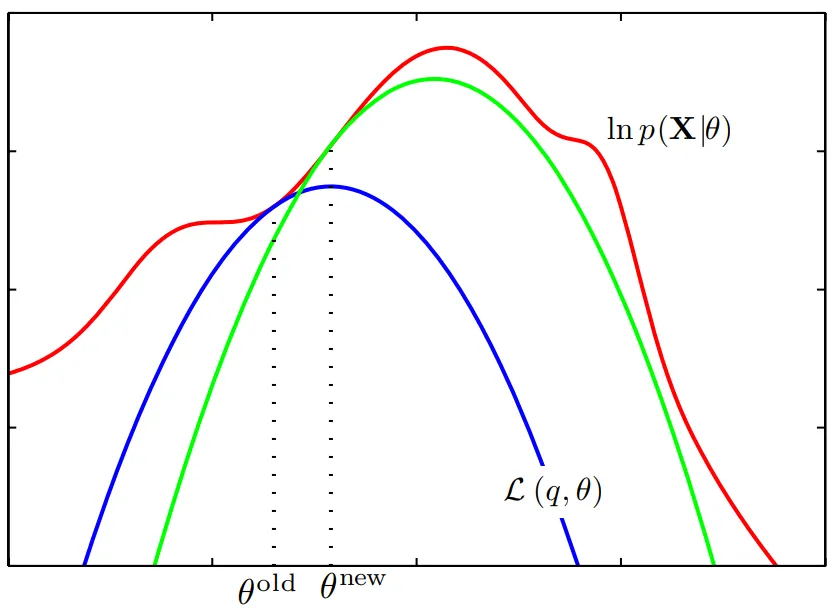
에서의 를 구해서(파란색 함수, 현재 단계에서 로그가능도의 의 하한) 이를 최대화 하는 를 를 통해 구한다. 마찬가지로 에서 로그 가능도의 하한(녹색 함수)을 구해 이를최대화하도록 를 업데이트하여 둘의 차이가 없을 때 까지 반복한다.