
.png&blockId=144b136a-1bb0-8113-9ce9-e792ad9bd009)

 오버 샘플링
오버 샘플링
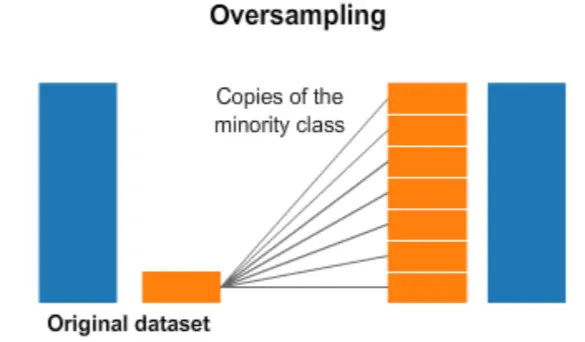
언더 샘플링 기법은 데이터를 제거하기 때문에 데이터셋의 샘플 수가 적은 상황이라면, 문제가 발생할 수 있다. 오버 샘플링 기법은 소수 클래스의 데이터를 증폭시키는 방법으로 클래스간 균형을 맞추는 방법이다.
그렇다면 어떠한 방법으로 소수 클래스의 데이터를 생성할 수 있을까?
가장 간단하게 소수 클래스의 기존 샘플을 무작위로 복제하여 데이터 세트의 크기를 증가시키는 방법이 있을 것이다. 즉, 새로운 데이터를 생성하는 것이 아닌 기존의 소수 클래스 데이터만 많아져서 비율을 맞추는 방법이다. 가장 단순한 방법이지만, 기존의 소수 데이터의 양만 증가하므로, 소수 클래스에 대한 과적합이 발생할 가능성이 커진다는 단점이 있다.
SMOTE (Synthetic Minority Oversampling TEchnique)
기존의 소수 클래스의 샘플을 무작위로 복제하여 클래스 비율을 맞추면 소수클래스에 대한 과적합이 발생할 위험이 있었다. 이에 대한 대안으로, SMOTE는 소수 클래스에 대한 새로운 데이터를 생성하는 방법이다.
SMOTE는 기존 소수 클래스의 데이터 포인트들 사이의 선형 보간을 통해 새로운 샘플을 생성하, 데이터의 다양성을 증가시켜 과적합을 피할 수 있다. 두개의 샘플을 선택하여 다음과 같은 방법으로 새로운 샘플을 생성한다.
는 임의로 선택한 소수 클래스의 샘플이고, 은 선택한 의 이웃들 가운데 임의로 뽑은 하나의 샘플이다. 이를 통해 새로 만들어진 샘플 은 와 그 이웃 데이터를 이은 직선 사이 어딘가에 위치할 것이다. 이를 그림으로 나타내면 다음과 같다.
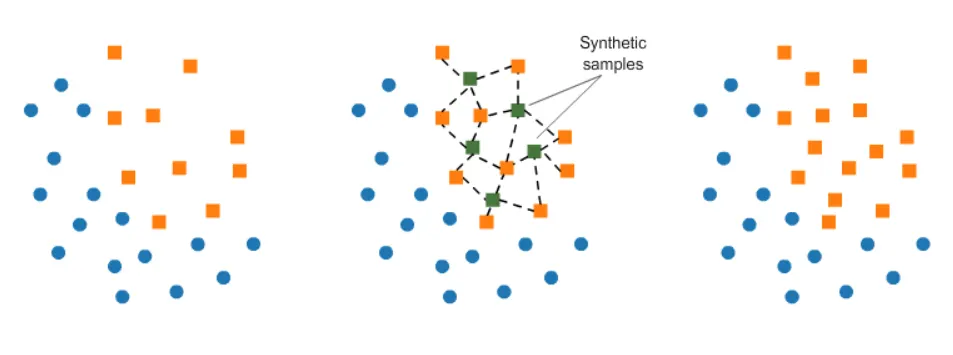
주황생 점들이 소수 클래스의 샘플들이고, 중앙 산점도에서 초록색 점들이 새로 만들어진 샘플들이다.
SMOTE 기법도 마찬가지로 imblearn 에서 제공되고 있다. 예시 코드는 다음과 같다.
from sklearn.datasets import make_classification
from imblearn.over_sampling import SMOTE
from collections import Counter
# 불균형 데이터 생성
X, y = make_classification(n_classes=2, class_sep=2,
weights=[0.1, 0.9], n_informative=3, n_redundant=1, flip_y=0,
n_features=20, n_clusters_per_class=1,
n_samples=1000, random_state=10)
print('Original dataset shape %s' % Counter(y))
# SMOTE 기법 적용
sm = SMOTE(random_state=42)
X_res, y_res = sm.fit_resample(X, y)
print('Resampled dataset shape %s' % Counter(y_res))
Python
복사
ADASYN (Adaptive Synthetic Sampling)
ADASYN기법은 SMOTE와 유사하지만 샘플링하는 소수 클래스 데이터 샘플의 개수를 위치에 마다 다르게 생성하는 방법이다. 클래스의 경계에 위치한 샘플들이 비교적 구별하는데 더 어려울 것이다. ADYSN은 이러한 경계점에 위치한 소수 클래스데이터의 샘플에 대해 더 많이 생성하여 모델의 학습능력을 향상시킬 수 있다.
ADYSN은 각 샘플마다 k개의 이웃에 속해 있는 샘플들 중 다른 클래스에 속한 샘플들의 비율을 계산하여 이를 가중치로 생성할 샘플들의 개수를 조절한다. 예시 코드는 다음과 같다.
from sklearn.datasets import make_classification
from imblearn.over_sampling import ADASYN
from collections import Counter
# 불균형 데이터셋 생성
X, y = make_classification(n_classes=2, class_sep=2,
weights=[0.1, 0.9], n_informative=3, n_redundant=1, flip_y=0,
n_features=20, n_clusters_per_class=1,
n_samples=1000, random_state=10)
print('Original dataset shape %s' % Counter(y))
# ADASYN 적용
ada = ADASYN(random_state=42)
X_res, y_res = ada.fit_resample(X, y)
print('Resampled dataset shape %s' % Counter(y_res))
Python
복사