
.png&blockId=144b136a-1bb0-8113-9ce9-e792ad9bd009)

 불균형한 데이터 다루기
불균형한 데이터 다루기
우리가 만나는 데이터중에서는 클래스간 불균형이 굉장히 큰 경우가 많다. 한 클래스의 수가 다른 클래스들보다 매우 많다거나, 적은 경우이다. 이진 분류로 예를 들면 정상적인 보험 처리 vs 보험사기 데이터, 온라인 구매 웹사이트의 방문객 vs 구매자 의 경우등이 있을 것이다. 통상적으로 클래스 수가 적은 보험 사기 사건의 클래스, 구매자의 경우등 중요한 카테고리를 1로 지정하여 분석을 진행한다. 이러한 불균형 데이터에서 모델링의 예측 성능을 향상시킬 수 있는 전처리 기법으로 언더 샘플링과 오버 샘플링 기법이 있다.
언더 샘플링
만약 데이터셋의 수가 충분히 크다면, 클래스 수가 적은 희귀 데이터의 수만큼 비율을 맞춰 나머지 클래스의 데이터의 일부를 버려서 비율을 맞춰줄 수 있을 것이다. 즉, 개수가 많은 클래스 데이터 중에서 일부만을 사용하는 방법이다. 그렇다면 얼마만큼의 데이터 수가 충분히 크다고 할 수 있을까? 이는 응용분야에 따라 달라지므로, 해당 데이터의 도메인 지식이 어느정도 필요하다.
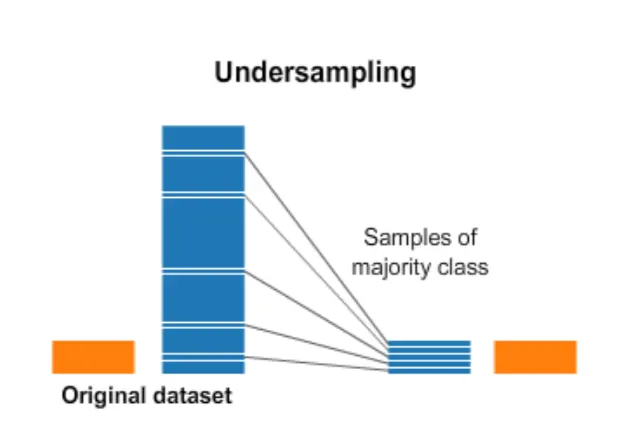
언더샘플링은 단순히 데이터를 제거하는 것이므로, 전반적인 데이터를 학습시간을 단축시킬 수 있다는 장점이 있다.
그렇다면 다수의 클래스에서 어떠한 기준으로 데이터를 제거해야 할까? 가장 단순하게 임의로 지정하여 데이터를 제거해볼 수 있을 것이다. 하지만 이 방법은 중요한 정보를 잃을 수 있다는 단점이 있다.
랜덤 언더샘플링은 판다스의 sample() 함수를 이용하여 다음과 같이 구현할 수 있다.
import pandas as pd
import numpy as np
# 불균형 데이터 생성
data = {'Class': ['A']*90 + ['B']*10}
df = pd.DataFrame(data)
df_majority = df[df['Class'] == 'A'] # 다수 클래스
df_minority = df[df['Class'] == 'B'] # 희귀 클래스
# 희귀 클래스 수만큼 다수 클래스에서 임의로 샘플링한다.
df_majority_under = df_majority.sample(len(df_minority))
# concat()함수를 이용하여 결합
df_under = pd.concat([df_majority_under, df_minority])
print(df_under['Class'].value_counts())
Python
복사
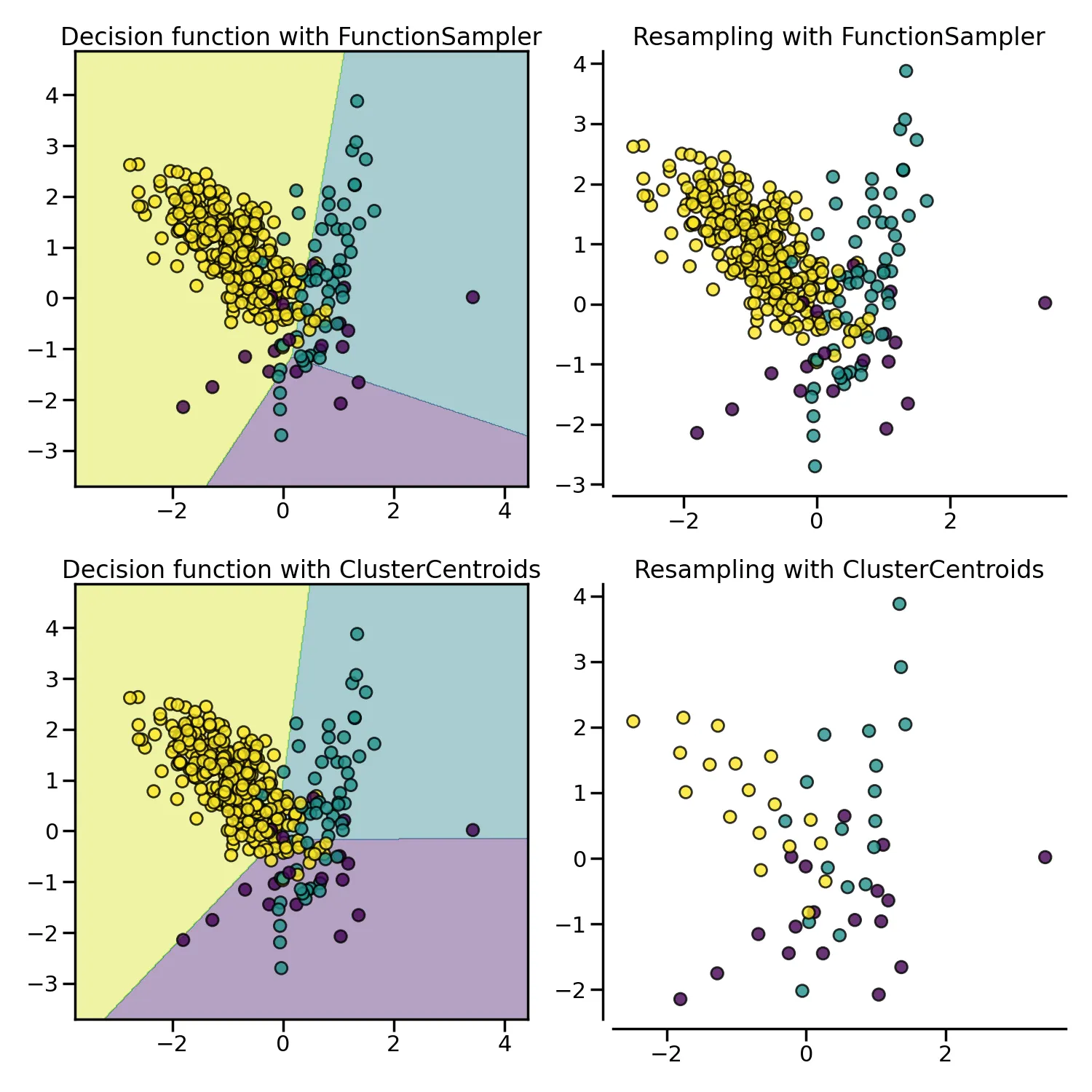
클래스 데이터의 분포를 가정하지 않고 랜덤으로 뽑는 것은 중요한 정보를 놓칠 수 있기에 가능한 한가지 방법은, 클래스마다 중심점을 설정하여 샘플링을 하는 것이다. 중심점은 K-Means와 같은 비지도 학습 알고리즘을 활용하여 샘플링을 진행한다. 이는 imblearn 에서 제공하는 ClusterCentroids 클래스를 활용하여 구현이 가능하다.
다음은 imbalanced-learn에서 제공하는 예시 코드이다.
from collections import Counter
from sklearn.datasets import make_classification
X, y = make_classification(n_samples=5000, n_features=2, n_informative=2,
n_redundant=0, n_repeated=0, n_classes=3,
n_clusters_per_class=1,
weights=[0.01, 0.05, 0.94],
class_sep=0.8, random_state=0)
print(sorted(Counter(y).items()))
from imblearn.under_sampling import ClusterCentroids
cc = ClusterCentroids(random_state=0)
X_resampled, y_resampled = cc.fit_resample(X, y)
print(sorted(Counter(y_resampled).items()))
Python
복사
다음은 클러스터 기반 언더샘플링을 적용한 데이터셋을 시각화한 것이다.
Q1. imbalanced-learn에서 제공하는 다양한 언더샘플링 기법들을 찾아보자.