
 가우시안 혼합 모델(Gaussian Mixture Model, GMM)이란?
가우시안 혼합 모델(Gaussian Mixture Model, GMM)이란?
가우시안 혼합모델(GMM)은 샘플이 모수가 알려지지 않은 여러개의 혼합된 가우시안 분포를 따를 것이라는 가정하는 확률모델이다.
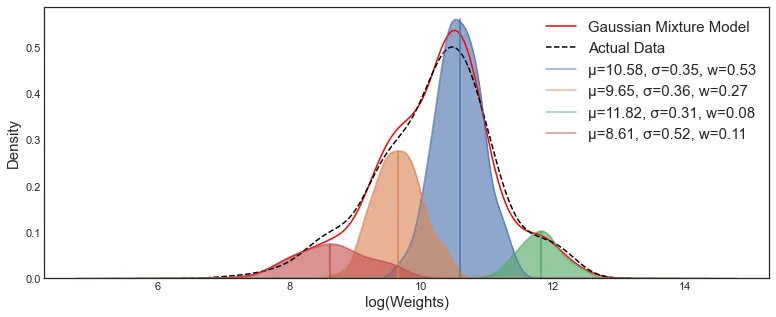
가우시안 혼합 분포는 다음과 같이 정의할 수 있다.
는 가우시안 혼합 분포에서 번째 가우시안 분포의 비율이다. 즉, GMM은 학습데이터 를 통해 를 추정하는 것이다. MLE를 통해 이를 추정해보자. 위 확률분포의 로그 가능도는 다음과 같다.
위 식을 각 모수에 대해 편미분을 통해 바로 최적의 해가 유도되지 않는다. 통계학에서는 이를 바로 구하기 힘들때 잠재변수(latent variable)를 두어 추정한다. 유도과정은 다음과 같다.
Q1. 위 로그가능도를 에 대해 편미분하여 왜 계산이 힘든지 알아보자.
GMM은 학습데이터 를 다음과 같이 생성되었다고 가정한다.
1.
샘플마다 개의 군집에서 랜덤하게 한 군집이 선택된다. 번째 군집을 선택할 확률은 로 정의된다. 샘플을위해 선택한 군집 인덱스는 로 표시한다. 각 인덱스 는 번째 군집에 군집에 속한다면, 번째 원소가 1이고 나머지는 0인 차원 컬럼 벡터로 표시할 수 있다. 즉 이다. 따라서, 이다.
2.
이면, 즉 샘플 가 번째 군집에 할당되었다면, 해당 샘플은 평균이 이고, 분산이 인 가우시안 분포에서 랜덤하게 샘플링된 것이다. 다시 말해서 이다.
위 과정을 그래프 모형으로 나타내면 다음과 같다.
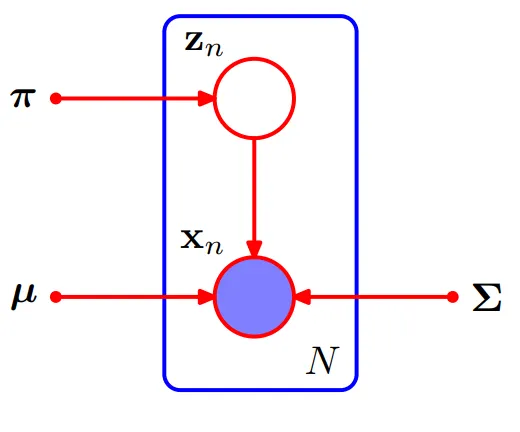
샘플 를 군집 인덱스 에 대한 결합 분포로 나타내면 이다. 이 결합확률 분포를 에 대한 주변 확률분포로 나타내면 다음과 같다.
즉, 대신, 를 통해 로그가능도를 최대화하는 것이 아닌, 로그가능도의 하한을 최대화하는 EM(Expectation-Maximization) 알고리즘을 통해 GMM을 학습한다. EM 알고리즘과 이를 통한 GMM의 학습과정은 다음시간에 알아보자.